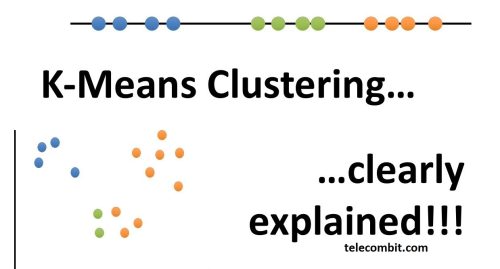
What is K-Means Clustering and What are its Real World Applications?
K-means clustering is a widely-used unsupervised machine learning algorithm that groups data points into distinct clusters based on their attributes. It is an essential tool in data analysis, providing valuable insights and aiding decision-making processes. By understanding the working principle of K-means clustering and exploring its real-world applications, businesses can harness its power to extract meaningful information from their datasets.
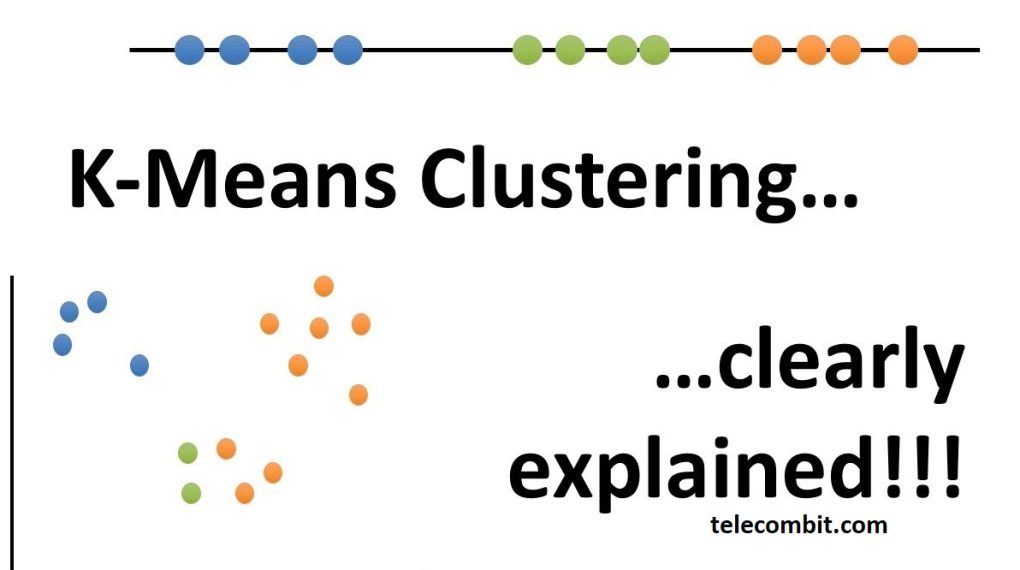
Understanding K-Means Clustering
K-means clustering operates on the principle of similarity. It groups data points together based on how closely they resemble each other in terms of their attributes. The algorithm aims to minimize the distance between data points within a cluster while maximizing the distance between different clusters. This technique enables analysts to identify patterns, similarities, and differences in the data without the need for pre-existing labels or classifications. The number of clusters, denoted by K, is determined by the analyst based on the specific problem or dataset.
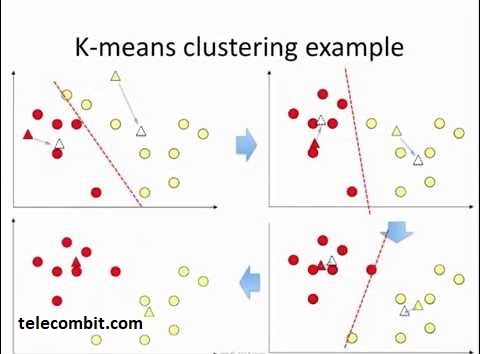
Working Principle of K-Means Clustering
Initialization: The K-means clustering process begins by initializing K cluster centers. These centers act as the starting points for grouping the data points. They can be randomly chosen from the dataset or placed strategically based on prior knowledge or domain expertise.
Assignment: In the assignment step, each data point is assigned to the nearest cluster center based on a defined distance metric, typically the Euclidean distance. The distance metric calculates the dissimilarity between a data point and each cluster center. The data point is then assigned to the cluster center with the minimum distance, forming an initial cluster grouping.
Update: After assigning all the data points to clusters, the algorithm recalculates the cluster centers. It does this by taking the mean of all the data points assigned to each cluster. This process moves the cluster center to the centroid (geometric center) of the data points in that cluster. The reassignment and update steps are repeated iteratively until the cluster centers stabilize and the algorithm converges.
Convergence: The convergence of the K-means algorithm occurs when the cluster centers no longer change significantly or when a specified number of iterations is reached. At this point, the algorithm has found a stable solution, and the data points are reliably grouped into clusters.

Real-World Applications of K-Means Clustering
K-means clustering finds applications in various domains, including:
Customer Segmentation: In the field of marketing, K-means clustering is employed to segment customers into distinct groups based on their purchasing behavior, demographics, or preferences. This information helps businesses tailor their marketing strategies to target specific customer segments effectively.
Image Compression: K-means clustering is utilized in image compression techniques to reduce the file size while maintaining visual quality. By clustering similar pixels together and replacing them with a single representative value, the algorithm can significantly reduce the amount of data required to represent an image.
Anomaly Detection: K-means clustering can be used to detect anomalies or outliers in datasets. By defining clusters based on normal behavior patterns, any data points that fall outside these clusters can be identified as anomalies. This approach is valuable in fraud detection, network security, and quality control.
Document Clustering: In the realm of natural language processing, K-means clustering assists in organizing documents into meaningful groups. By analyzing the similarity of document contents, the algorithm can categorize them into clusters, enabling efficient document management, topic modeling, and information retrieval.
Conclusion
K-means clustering is a versatile and powerful algorithm that enables businesses to uncover insights and patterns within their data. By understanding its working principle and exploring its real-world applications, organizations can leverage K-means clustering to enhance decision-making, improve customer targeting, optimize resource allocation, and drive innovation in various domains. As data continues to grow in complexity.





